
A Gentle Introduction to Gradient Boosting
A Brief History of Gradient Boosting I Invent Adaboost, the rst successful boosting algorithm [Freund et al., 1996, Freund and Schapire, 1997] I Formulate Adaboost as gradient descent with a special loss function[Breiman et al., 1998, Breiman, 1999] I Generalize Adaboost to Gradient Boosting in order to handle a variety of loss functions
Download A Gentle Introduction to Gradient Boosting
Information
Domain:
Source:
Link to this page:
Documents from same domain

Wireless Communications and Networks
www.ccs.neu.eduWireless Networks Spring 2005 Wireless Comes of Age Guglielmo Marconi invented the wireless telegraph in 1896 o Communication by encoding alphanumeric characters in …

Introduction to Machine Learning - College of Computer and ...
www.ccs.neu.edu3 CSG220: Machine Learning Introduction: Slide 5 • Given experience in some problem domain, improve performance in it • game-playing • robotics • Rote learning qualifies, but more interesting
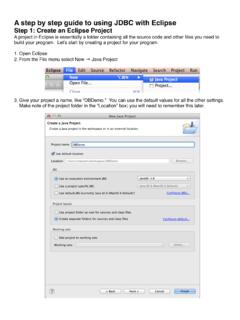
A step by step guide to using JDBC with Eclipse Step 1 ...
www.ccs.neu.edu4. Press Finish to create the project 5. Eclipse might ask you whether you want to switch to the Java perspective. If so, say Yes. 6. You should see an empty project which looks something like this.

Creating a text-based editor for Eclipse
www.ccs.neu.eduEclipse is an open source framework for building Integrated Development Environment using a pre-built set of tools and GUI Components. It has generated interest from many developers since it
A Gentle Introduction to Gradient Boosting
www.ccs.neu.eduWhat is Gradient Boosting Gradient Boosting = Gradient Descent + Boosting Gradient Boosting I Fit an additive model (ensemble) P t ˆ th t(x) in a forward stage-wise manner. I In each stage, introduce a weak learner to compensate the shortcomings of existing weak learners.

Decision Trees - College of Computer and Information Science
www.ccs.neu.eduDecision Trees Assume we are given the following data: ... input attributes aka features. A description of these features is provided in Figure-2. Figure 2: The available input attributes (features) and their brief descriptions. ... The x-axis in both cases is the probability that an instance belongs to class 1, and in (b) the entropy function ...

Why Flappy Bird Is / Was So Successful And Popular But So ...
www.ccs.neu.eduinterface between man and machine, or in the case of Flappy Bird, the interface between the game player and the game. If a UX designer is unaware of basic cognitive science including an understanding of what makes things complex to learn and use, this can be a major problem.

Antennas & Propagation
www.ccs.neu.eduLine-of-Sight Propagation Above 30 MHz neither ground nor sky wave propagation operates Transmitting and receiving antennas must be within line of sight

Marginal and conditional distributions of multivariate ...
www.ccs.neu.eduMarginal and conditional distributions of multivariate normal distribution Assume an n-dimensional random vector has a normal distribution with where and are two subvectors of respective dimensions and with . Note that , and. Theorem 4: Part a The marginal distributions of and are also normal with mean vector and covariance matrix

Multivariate normal distribution
www.ccs.neu.eduor to make it explicitly known that X is k-dimensional, with k-dimensional mean vector and k x k covariance matrix Definition A random vector x = (X1, …, Xk)' is said to have the multivariate normal distribution if it satisfies the following equivalent conditions.[1] Every linear combination of its components Y = a1X1 + … + akXk is normally distributed. . That is, for any constant v
Related documents

Introduction to boosted decision trees
indico.fnal.govGradient boosting 2. When and how to use them Common hyperparameters Pros and cons 3. Hands-on tutorial Uses xgboost library (python API) See next slide 2.

LightGBM: A Highly Efficient Gradient Boosting Decision …
www.microsoft.comGradient boosting decision tree (GBDT) [1] is a widely-used machine learning algorithm, due to its efficiency, accuracy, and interpretability. GBDT achieves state-of-the-art performances in many machine learning tasks, such as multi-class classification [2], click prediction [3], and learning to rank [4].

Greedy Function Approximation: A Gradient Boosting …
biostat.jhsph.edu1987), MARS (F riedman 1991), w a v elets (Donoho 1993), and supp ort v ector mac hines (V apnik 1995). Of sp ecial in terest here is the case where these functions

CS 229 Project Report: Predicting Used Car Prices
cs229.stanford.edumetric is the gradient of the loss function. This model was chosen to account for non-linear relationships between the features and predicted price, by splitting the data into 100 regions. 4. XGBoost Extreme Gradient Boosting or XGBoost [4] is one of the most popular machine learning models in current times. XGBoost is quite similar at the core ...

勾配ブースティング Gradient Boosting
datachemeng.com0 勾配ブースティング Gradient Boosting 明治大学理⼯学部応用化学科 データ化学⼯学研究室⾦⼦弘昌

XGBoost: A Scalable Tree Boosting System
dmlc.cs.washington.edugradient tree boosting. 2.2 Gradient Tree Boosting The tree ensemble model in Eq. (2) includes functions as parameters and cannot be optimized using traditional opti-mization methods in Euclidean space. Instead, the model is trained in an additive manner. Formally, let ^y(t) i be the prediction of the i-th instance at the t-th iteration, we ...

Home | Department of Statistics
jerryfriedman.su.domainsÝjØ Þ ÑmÏ7Ö 896 ÑaÓxÎ;Ï çPÛaØ ËaÖ Ô BA ÕZË Ø ÛmÛmÙ ÕVçPÔ ÎaØ Ù Ì7â Ô Ë5Ì ÕZËâ5Ø ËaÜ Ô Þ > 5ø,âjÙxØZÜPÔ Ø Þ

Gradient Descent - CMU Statistics
stat.cmu.eduGradient boosting: basically a version of gradient descent that is forced to work with trees First think of optimization as min u, = ;u) )) + ...

XGBoost: A Scalable Tree Boosting System
www.kdd.orggradient tree boosting [10]1 is one technique that shines in many applications. Tree boosting has been shown to give state-of-the-art results on many standard classi cation benchmarks [16]. LambdaMART [5], a variant of tree boost-ing for ranking, achieves state-of-the-art result for ranking 1Gradient tree boosting is also known as gradient boosting