Search results with tag "Derating"

Power MOSFET Avalanche Design Guidelines
www.vishay.cominstead, a voltage derating is maintained between rated BVDSS and VDD (typically 90 % or less). In such instances, however, it is not uncommon that greater than planned for voltage spikes can occur, so even the best designs may encounter an infrequent avalanche event. One such example, a flyback converter, is shown in figures 1 to 3.

US1A - US1M
www.diodes.comFig. 1 Forward Current Derating Curve T ° 0.01 0.1 1.0 10 00.4 0.8 I, I N S T A N T A N E O U S FO R WA R D C U R R E N T (A) F V , INSTANTANEOUS FORWARD VOLTAGE (V) Fig. 2 Typical Forward Characteristics F 1.2 1.6 2.0 US1A - US1D US1G US1J - US1M

Owner’s Manual & Safety Instructions
manuals.harborfreight.com(80 percent derating) which may apply. 10. Panel must be connected using UL listed outdoor rated wire of the correct thickness (gauge) for the amperage rating and length (see warning number 9 also). Follow the guidelines in the chart below: current in amps Maximum Length 5' 10' 15' 20' 25' 0-5 18 6-7 18 16 8 18 16 10 18 16 11-12 16 14 15 14 12 18

Guide to Fuse Selection - Schurter
ch.schurter.comDerating-curve UMT 250 (see data sheet) www.schurterinc.com Fuse Selection Guide 10 Heat Issues > Heat dissipated from fuses can affect other components in close proximity and vice versa. > Sufficient airflow and ventilation should be considered when designing fuses in …

Standard LED - Farnell
www.farnell.comDerating Linear From 50°C 0.4 mA / °C Reverse Voltage 5 V Operating Temperature Range -25°C to +80°C Storage Temperature Range -40°C to +100°C Lead Soldering Temperature (4 mm (0.157) Inches from Body) 260°C for 5 s Absolute Maximum Ratings at Ta = 25°C Parameter Symbol Minimum Typical Maximum Unit Test Condition

未命名 -1
www.meanwell.comDerating Curve Static Characteristics AMBIENT TEMPERATURE (℃) L O A D (%) 20 40 60 80 100-25 70 (HORIZONTAL) I/P FG EMI RECTIFIERS PWM CONTROL RECTIFIERS & FILTER +V-V POWER DETECTION SWITCHING CIRCUIT FILTER 115/230V(SW) fosc : 65KHz Block Diagram RECTIFIERS & FILTER FAN FAN ON/OFF CONTROL-20-10 0 10 20 30 40 50 60 L …

Gradient, divergence, and curl Math 131 Multivariate Calculus
mathcs.clarku.edur= @ @x 1; @ @x 2;:::; @ @x n which, when applied to f yields rf. This ris called the del operator. We can treat this del operator like a vector itself. We can combine it with other vector operations like dot product and cross product, and that leads to the concepts of divergence and curl, respectively. De nition 1. We de ne the divergence of a ...

1 Overview 2 The Gradient Descent Algorithm
people.seas.harvard.eduAlgorithm1GradientDescent 1: Guessx(0),setk 0 2: whilejjrf(x(k))jj do 3: x(k+1) = x(k) t krf(x(k)) 4: k k+ 1 5: endwhile 6: return x(k) f(x) x x(0) f(x 1) x(2)!f(z) x ...

Economic Growth and Subjective Well-Being: Reassessing the ...
www.nber.orgEvaluating these strong policy prescriptions demands a robust understanding of the true relationship between income and well-being. Unfortunately, the present literature is based on fragile and incomplete evidence about this ... well-being-income gradient estimated within and across countries at a point in time as well as over time, rather than its

Learning Structured Representation for Text Classification ...
www.microsoft.comgradient methods (Sutton et al. 2000), aiming to maximize the expected reward as shown below. J() = E (s t;a t)˘P (s t;a t)r(s 1a 1 s La L) = X s 1a 1 s La L P (s 1a 1 s La L)R L = X s 1a 1 s La L p(s 1) Y t ˇ (a tjs t)p(s t+1js t;a t)R L = X s 1a 1 s La L Y t ˇ (a tjs t)R L: Note that this reward is computed over just one sample, say X= x ...

5.0 AASHTO Controlling Design Criteria
azdot.govThe proposed gradient will be greater than the 4% maximum in the following location: I-40 WB MP 209.45 to MP 209.74 – 0.45% greater than the maximum 5.2.7 Cross Slope The existing cross slopes of 1.5% to 2.0% conform to AASHTO’s current design criteria. The proposed cross slopes will be 2.0%, as required by the RDG.

What is El Niño & La Niña? - National Weather Service
www.weather.govWhen different parts of the tropical ocean warm and cool and the pressure gradients shift, the atmospheric wind patterns also shift to alter precipitation patterns. Because each El Niño and La Niña event has unique characteristics of timing, intensity …

Proximal Gradient Descent - Carnegie Mellon University
www.stat.cmu.eduOften called theiterative soft-thresholding algorithm (ISTA).1 Very simple algorithm Example of proximal gradient (ISTA) vs. subgradient method convergence curves 0 200 400 600 800 1000 0.02 0.05 0.10 0.20 0.50 k f-fstar Subgradient method Proximal gradient 1Beck and Teboulle (2008), \A fast iterative shrinkage-thresholding algorithm for linear ...

Estimation of Stress on Ship Structures Using Full-Scale ...
www.classnk.or.jpgradient boosting for estimation of probability distributions. Gradie nt boosting is a type of ensemble learning method that cre ates one learner by combining multiple weak learners with low estimation accuracy. A feature of NGBoost is that it uses natural

Highways Guidance Note - Gradients
www.kirklees.gov.ukHighways Guidance Note – Gradients 4 March 2019 (v2) 31 Consideration shall be given to increasing carriageway widths to accommodate cyclists’ increased wobble. 32 The risk of vehicles losing control and the implication for any development in the ‘run-off’ area at the foot of the slope shall be assessed.

Beyond a Gaussian Denoiser: Residual Learning of Deep …
www4.comp.polyu.edu.hkand boosting the denoising performance. While this paper aims to design a more effective Gaussian denoiser, we observe that when v is the difference between the ... gradient-based optimization algorithms [35], [36], [37], batch normalization [28] and …

Logistic Regression - Rutgers University
stat.rutgers.edu• It is used in Neural Nets and Gradient Boosting (MART) 11. Newton’s Method Recall the goal is to find the x ...

Florida Surgeon General Promotes Nutraceuticals for COVID
media.mercola.comconsistency of evidence, temporality, biological gradient, plausibility or mechanism of. action, and coherence, although coherence still needs to be veried experimentally) that ... Boosting your overall immune function b y modulating your innate and adaptiv e: immune responses.

XGBoost: A Scalable Tree Boosting System
dmlc.cs.washington.edugradient tree boosting. 2.2 Gradient Tree Boosting The tree ensemble model in Eq. (2) includes functions as parameters and cannot be optimized using traditional opti-mization methods in Euclidean space. Instead, the model is trained in an additive manner. Formally, let ^y(t) i be the prediction of the i-th instance at the t-th iteration, we ...

Gradient Episodic Memory for Continual Learning
proceedings.neurips.ccIn this section, we propose Gradient Episodic Memory (GEM), a model for continual learning, as introduced in Section 2. The main feature of GEM is an episodic memory M t, which stores a subset of the observed examples from task t. For simplicity, we assume integer task descriptors, and use them to index the episodic memory.

Policy Gradient Methods for Reinforcement Learning with ...
proceedings.neurips.cclearns much more slowly than RL methods using value functions and has received relatively little attention. Learning a value function and using it to reduce the variance of the gradient estimate appears to be ess~ntial for rapid learning. Jaakkola, Singh

2 Heat Equation - Stanford University
web.stanford.eduthe temperature gradient. The only way heat will leave D is through the boundary. That is, dH dt = Z @D •ru¢ndS: where @D is the boundary of D, n is the outward unit normal vector to @D and dS is the surface measure over @D. Therefore, we have Z D c‰ut(x;t)dx = Z @D •ru¢ndS: Recall that for a vector field F, the Divergence Theorem says ...

10-725: Optimization Fall 2012 Lecture 5: Gradient Desent ...
www.cs.cmu.edu5.1.3 Exact line search At each iteration, do the best e can along the direction of the gradient, t= argmin s 0 f(x srf(x)): Usually, it is not possible to do this minimization exactly. Approximations to exact line search are often not much more e cient than backtracking, and it’s not worth it.

Equations of straight lines
www.mathcentre.ac.ukthe gradient would be −2. In general, therefore, the equation y = mx represents a straight line passing through the origin with gradient m. Key Point The equation of a straight line with gradient m passing through the origin is given by y = mx. 3. The yintercept of a line Consider the straight line with equation y = 2x+1.

A User's Guide to DMU
dmu.ghpc.au.dk2: Preconditioned Conjugate Gradient. scaling: 0: no scaling of data prior to computation = 1: data are scaled to unit residual variance before computations. Estimated parameters and effects are scaled back to the original units. test_prt = 0: Standard. Yield minimum amount of output 1: Standard output plus lists of all class levels and

Australian House Prices 1880-2005 - UNSW Business School
www.business.unsw.edu.aurent gradients c b a` c` b` 0. Impact of greenbelt on rental value. distance from CBD rental value location rent rental value of rural land green belt urban fringe CBD rent gradients a b rental on capital cost of conversion c a` c` b` 0. Sydney Median House Price Series $"000, 2005 0 100 200 300 400 500 600

Directional Derivatives and The Gradient Vector
www.personal.psu.eduHere is a good thought exercise to test your understanding of gradients. What do you think the gradient vector should be for the function f(x,y)=x2 +y2 at the point (0,0)?Remember, this function is the paraboloid and (0,0) is its vertex. 115 of 142

Lecture 5: Stochastic Gradient Descent - Cornell University
www.cs.cornell.eduStochastic gradient descent (SGD).Basic idea: in gradient descent, just replace the full gradient (which is a sum) with a single gradient example. Initialize the parameters at some value w 0 2Rd, and decrease the value of the empirical risk iteratively by sampling a random index~i tuniformly from f1;:::;ng and then updating w t+1 = w t trf ~i t ...

The group lasso for logistic regression
people.ee.duke.edulogistic regression models and proposed a gradient descent algorithm to solve the correspond-ing constrained problem. We present methods which allow us to work directly on the penalized problem and whose convergence property does not depend on …

Learning to Reweight Examples for Robust Deep Learning
proceedings.mlr.pressobjective towards an online approximation that can fit into any regular supervised training. We give a practical implementation suitable for any deep network type and provide theoretical guarantees under mild conditions that our algorithm has a convergence rate of O(1= 2). Note that this is the same as that of stochastic gradient descent (SGD ...
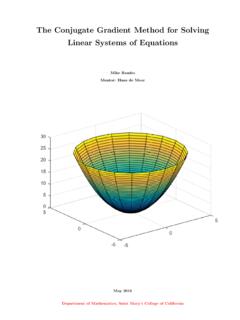
The Conjugate Gradient Method for Solving Linear …
math.stmarys-ca.edu2 Relevant De nitions and Notation Throughout this paper, the following de nitions and terminology will be utilized for the cg-method. De ntion 2.1.Partial Di erential Equations (PDEs): an equation in which the solution is a function which has two or more independent variables. Remark. The cg-method is utilized to estimate solutions to linear PDEs.

Projected Gradient Algorithm
angms.scienceOct 23, 2020 · Q(:) is a function from Rnto Rn, and itself is an optimization problem: P Q(x 0) = argmin x2Q 1 2 kx x 0k2 2: I PGD is an \economic" algorithm if the problem is easy to solve. This is not true for general Qand there are lots of constraint sets that are very di cult to project onto. I If Qis a convex set, the optimization problem has a unique ...

Inkscape Tutorial - Babraham Institute
www.bioinformatics.babraham.ac.uk• Draw straight lines / curves • Calligraphy tool • Add text • Sculpt with spray • Erase • Fill ... –Circle vs segment vs arc. Creating basic shapes. Creating basic shapes ... •Fill = Colour/Gradient/Pattern within a shape •Stroke = The line around a shape •Object > Fill and Stroke (Shift+Ctrl+F)

Mark Scheme (Results) - Edexcel
qualifications.pearson.comAug 22, 2018 · correct line between x = −1 and x = 3 3 B3 for a correct line between x = −1 and x = 3 If not B3 then award B2 for a straight line segment through at least 3 of OR for all of plotted and not joined OR for a line drawn through (0, 4) with a clear attempt at a gradient of −2 (eg a line through (0, 4) and (0.5, 2)

Mark Scheme (Results) Summer 2019
qualifications.pearson.comAug 22, 2019 · (B2 for a correct straight line segment through at least 3 of ... OR for a line drawn with a positive gradient through (0, −3) and clear intention to use a gradient of 2, eg line through (0,−3) going across 2 squares and up 4 squares ) Ignore any incorrect points. Points need not be plotted for a correct line (segment) drawn Table of values ...
YEAR 11 GCSE MATHS REVISION CHECKLIST FOUNDATION …
foresthill.lewisham.sch.uk9.1 Coordinates Find the midpoint of a line segment. Recognise, name and plot straight-line graphs parallel to the axes. 9.2 Linear graphs Generate and plot coordinates from a rule. Plot straight-line graphs from tables of values. Draw graphs to represent relationships. 9.3 Gradient Find the gradient of a line. Identify and interpret the ...

Name: GCSE (1 – 9) The Equation of a Line
www.mathsgenie.co.uk3. A straight line has equationy=5–3x (a) Write down the gradient of the line. (b) Write down the coordinates of the point where the line crosses the y axis.

5.8 Lagrange Multipliers - Pennsylvania State University
www.personal.psu.eduThis will given you a system of equations based on the components of the gradients. 2. Solve this system of equations to get x, y,and.(Theremaybemultiplesolutions.) 3. For each of these solutions, find f(x,y)andcomparethevaluesyouget.Everysolutionthat gives a maximum value is a maximum point, and every solution that gives a minimum value

1.4 Gradient, Divergenz und Rotation - Markus Engelhardt
markusengelhardt.com1.4 Gradient, Divergenz und Rotation 19 Abbildung 2: Feldlinienverlauf bei positiver Divergenz x x BEISPIEL f(x;y;z) = 0 @ x 2y 3z 1 A divf= rf= 1 + 2 + …
01. Coordinate Geometry of the Straight Line (A)
irp-cdn.multiscreensite.comThe line has a gradient of 2. The line has a gradient of −C D. Since, The lines are perpendicular to each other. Example 4 Find the equation of the line passing through O and perpendicular to the line . Solution By expressing the equation in the form The gradient of the given line is …

TECHNICAL FIRE SAFETY GUIDANCE NOTE
www.essex-fire.gov.ukThis Guidance Note covers the access arrangements needed for fire appliances to get close ... 3.1 Access roads may be public highways, private roads, footpaths or specially strengthened and ... 4.3 Gradients on any access road to be used by fire appliances should be no greater than 1 in 4

Lecture 2: The SVM classifier - University of Oxford
www.robots.ox.ac.ukoptimization algorithm (such as gradient descent)? local minimum global minimum If the cost function is convex, then a locally optimal point is globally optimal (provided the optimization is over a convex set, which it is in our case) Optimization continued. Convex functions.

6.1 Gradient Descent: Convergence Analysis
www.stat.cmu.eduLecture 6: September 12 6-3 6.1.2 Convergence of gradient descent with adaptive step size We will not prove the analogous result for gradient descent with backtracking to adaptively select the step size. Instead, we just present the result with a few comments.

Model-Agnostic Meta-Learning for Fast Adaptation of Deep ...
arxiv.orgusing one or more gradient descent updates on task T i. For example, when using one gradient update, 0 i = r L T i (f): The step size may be fixed as a hyperparameter or meta-learned. For simplicity of notation, we will consider one gradient update for the rest of this section, but using multi-ple gradient updates is a straightforward extension.

Translating Embeddings for Modeling Multi-relational Data
proceedings.neurips.ccThe optimization is carried out by stochastic gradient descent (in minibatch mode), over the possible h;‘ and t, with the additional constraints that the L 2-norm of the embeddings of the entities is 1 (no regularization or norm constraints are given to the label embeddings ‘).This constraint is important

5. Straight Line Graphs Answers - Rastrick High School
www.rastrick.calderdale.sch.ukA line has a gradient 0t 8 and passes through the (2, 3). Find the equation Of the line. c: -13 A tine has a gradient of —'h and passes through the point Find the equation of the line. 13 (3) 5. A straight line L is shown on the grid. Work out the equation of line L

Conjugate Gradient Method - Stanford University
stanford.edu• proposed by Hestenes and Stiefel in 1952 (as direct method) • solves SPD system Ax = b – in theory (i.e., exact arithmetic) in n iterations – each iteration requires a few inner products in Rn, and one matrix-vector multiply z → Az • for A dense, matrix-vector multiply z → Az costs n2, so total cost is n3, same as direct methods
Similar queries
Power MOSFET Avalanche Design Guidelines, Voltage derating, Voltage, Derating Curve, Derating, Guidelines, Guide to Fuse Selection, Derating-curve, Gradient, Gradient descent, Policy, Learning, Gradient methods, AASHTO, National Weather Service, Gradients, Proximal Gradient Descent, Thresholding, Gradient Boosting, Gradie nt boosting, Highways Guidance Note - Gradients, Highways Guidance Note – Gradients, Development, A Gaussian Denoiser: Residual Learning of, Boosting, XGBoost: A Scalable Tree Boosting System, Gradient Episodic Memory, Memory, Policy Gradient Methods, Methods, Heat Equation, 725: Optimization Fall 2012 Lecture 5, Line, Straight, Straight line, Of a straight line, Conjugate Gradient, Lecture 5: Stochastic Gradient Descent, Group lasso, Approximation, Conjugate Gradient Method for Solving Linear, Equations, Projected Gradient Algorithm, Optimization, Convex, Segment, Straight line segment, Line segment, The Equation of a Line, Gradient, Divergenz und Rotation, Guidance Note, Highways, 1 Gradient Descent, Lecture, September, Embeddings, Straight Line Graphs, Direct