Example: tourism industry
Efficient Large-Scale Language Model Training on GPU ...
would require approximately 288 years with a single V100 NVIDIA GPU). This calls for parallelism. Data-parallel scale-out usually works well, but suffers from two limitations: a) beyond a point, the per-GPU batch size becomes too small, reducing GPU utilization and increasing communication cost, and b) the maximum number
Tags:
Information
Domain:
Source:
Link to this page:
Documents from same domain
![arXiv:0706.3639v1 [cs.AI] 25 Jun 2007](/cache/preview/4/1/3/9/3/1/4/b/thumb-4139314b93ef86b7b4c2d05ebcc88e46.jpg)
arXiv:0706.3639v1 [cs.AI] 25 Jun 2007
arxiv.orgarXiv:0706.3639v1 [cs.AI] 25 Jun 2007 Technical Report IDSIA-07-07 A Collection of Definitions of Intelligence Shane Legg IDSIA, Galleria …

Deep Residual Learning for Image Recognition - …
arxiv.orgDeep Residual Learning for Image Recognition Kaiming He Xiangyu Zhang Shaoqing Ren Jian Sun Microsoft Research fkahe, v-xiangz, v-shren, jiansung@microsoft.com
![arXiv:1301.3781v3 [cs.CL] 7 Sep 2013](/cache/preview/4/d/5/0/4/3/4/0/thumb-4d504340120163c0bdf3f4678d8d217f.jpg)
arXiv:1301.3781v3 [cs.CL] 7 Sep 2013
arxiv.orgFor all the following models, the training complexity is proportional to O = E T Q; (1) where E is number of the training epochs, T is the number of …
![@google.com arXiv:1609.03499v2 [cs.SD] 19 Sep 2016](/cache/preview/c/3/4/9/4/6/9/b/thumb-c349469b499107d21e221f2ac908f8b2.jpg)
@google.com arXiv:1609.03499v2 [cs.SD] 19 Sep 2016
arxiv.orgwhere 1 <x t <1 and = 255. This non-linear quantization produces a significantly better reconstruction than a simple linear quantization scheme. …

A Tutorial on UAVs for Wireless Networks: …
arxiv.orgA Tutorial on UAVs for Wireless Networks: Applications, Challenges, and Open Problems Mohammad Mozaffari 1, ... to UAVs in wireless communications is the work in …

Adversarial Generative Nets: Neural Network …
arxiv.orgAdversarial Generative Nets: Neural Network Attacks on State-of-the-Art Face Recognition Mahmood Sharif, Sruti Bhagavatula, Lujo Bauer Carnegie Mellon University

Massive Exploration of Neural Machine Translation ...
arxiv.orgMassive Exploration of Neural Machine Translation Architectures Denny Britzy, Anna Goldie, Minh-Thang Luong, Quoc Le fdennybritz,agoldie,thangluong,qvlg@google.com Google Brain

Mastering Chess and Shogi by Self-Play with a …
arxiv.orgMastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm David Silver, 1Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, 1Matthew Lai, Arthur Guez, Marc Lanctot,1

Going deeper with convolutions - arXiv
arxiv.orgGoing deeper with convolutions Christian Szegedy Google Inc. Wei Liu University of North Carolina, Chapel Hill Yangqing Jia Google Inc. Pierre Sermanet

Andrew G. Howard Menglong Zhu Bo Chen Dmitry ...
arxiv.orgMobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications Andrew G. Howard Menglong Zhu Bo Chen Dmitry Kalenichenko Weijun Wang Tobias Weyand Marco Andreetto Hartwig Adam
Related documents

NVIDIA TESLA V100 GPU ARCHITECTURE
images.nvidia.comV100 GPU ARCHITECTURE Since the introduction of the pioneering CUDA GPU Computing platform over 10 years ago, each new NVIDIA® GPU generation has delivered higher application performance, improved power efficiency, added important new compute features, and simplified GPU programming. Today,

Gaussian 16 Source Code Installation Instructions, Rev. C
gaussian.comwill build with NVIDIA K40, K80, P100 and V100 GPU support and the current type of x86_64 processor. Use a command like this one: % bsd/bldg16 all volta sandybridge to turn on both GPU support and a particular CPU type.

GPU Computing Guide - updates.cst.com
updates.cst.comGPU Computing needs to be enabled via the acceleration dialog box before running a simu-lation. To turn on GPU Computing: 1. Open the dialog of the solver. ... Tesla V100-SXM2-32GB (Chip) Volta Servers 2018 SP6 Tesla V100-PCIE-32GB Volta Servers 2018 SP6 Tesla V100-SXM2-16GB (Chip) Volta Servers 2018 SP1

GPU Accelerator Capabilities
www.ansys.comGPU Accelerator Capabilities * ... V100 Windows x64 Windows Server 2019 EMIT. Application Manufacturer Product Series Card / GPU Tested Platform Tested Operating System Version NVIDIA Ampere A100 Liniux x64 Red Hat 7.8 Quadro GP100 Windows x64 Windows 10 GV100 Windows x64 Windows 10
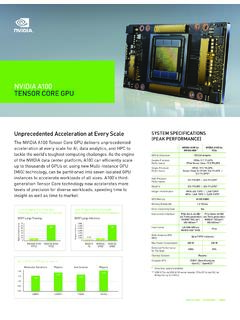
NVIDIA A100 | Tensor Core GPU
www.nvidia.comNVIDIA V100 FP32 1X 6X BERT Large Training 1X 7X Up to 7X Higher Performance with Multi-Instance GPU (MIG) for AI Inference2 0 4,000 7,000 5,000 2,000 Sequences/second 3,000 NVIDIA A100 NVIDIA T4 1,000 6,000 BERT Large Inference 0.6X NVIDIA V100 1X

NVIDIA DGX A100 | The Universal System for AI Infrastructure
images.nvidia.comThe A100 80GB GPU increases GPU memory bandwidth 30 percent over the A100 40GB GPU, making it the world’s first with 2 terabytes per second (TB/s). It also has significantly more on-chip memory than the previous-generation NVIDIA GPU, including a 40 megabyte (MB) level 2 cache that’s nearly 7X larger, maximizing compute performance.

GPU Computing Guide
updates.cst.com8 3DS.COM/SIMULIA c Dassault Systèmes GPU Computing Guide 2022 • Please note that cards of different generations (e.g. "Ampere" and "Volta") can’t be combined in a single host system for GPU Computing. • Platform = Servers: These GPUs are only available with a passive cooling system which only provides sufficient cooling if it’s used in combination with additional fans.