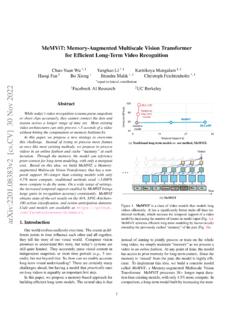
Transcription of Number of parameters (M)
1 YOLOX: Exceeding YOLO Series in 2021 Zheng Ge Songtao Liu Feng Wang Zeming Li Jian SunMegvii Technology{gezheng, liusongtao, wangfeng02, lizeming, " " " $ " " # # ! " # 3940414243444546474849505158111417202326 293235384144 COCO AP (%)V100 batch 1 Latency (ms) AP (%) Number of parameters (M)YOLOX-NanoNanoDetYOLOv4-TinyYOLOX-Tin yEfficientDet-Lite0 EfficientDet-Lite3 YOLOX-SPPYOLO-TinyEfficientDet-Lite2 EfficientDet-Lite1 Figure 1: Speed-accuracy trade-off of accurate models (top) and Size-accuracy curve of lite models on mobile devices(bottom) for YOLOX and other state-of-the-art object this report, we present some experienced improve-ments to YOLO series, forming a new high-performancedetector YOLOX. We switch the YOLO detector to ananchor-free manner and conduct other advanced detectiontechniques, , a decoupled head and the leading labelassignment strategy SimOTA to achieve state-of-the-art re-sults across a large scale range of models: For YOLO-Nano with only parameters and FLOPs, weget AP on COCO, surpassing NanoDet by AP;for YOLOv3, one of the most widely used detectors in in-dustry, we boost it to AP on COCO, outperform-ing the current best practice by AP; for YOLOX-Lwith roughly the same amount of parameters as YOLOv4-CSP, YOLOv5-L, we achieve AP on COCO at aspeed of FPS on Tesla V100, exceeding YOLOv5-Lby AP.}
2 Further, we won the 1st Place on StreamingPerception Challenge (Workshop on Autonomous Drivingat CVPR 2021) using a single YOLOX-L model. We hopethis report can provide useful experience for developers and* Equal contribution. Corresponding in practical scenes, and we also provide de-ploy versions with ONNX, TensorRT, NCNN, and Openvinosupported. Source code is IntroductionWith the development of object detection, YOLO se-ries [23, 24, 25, 1, 7] always pursuit the optimal speed andaccuracy trade-off for real-time applications. They extractthe most advanced detection technologies available at thetime ( , anchors [26] for YOLOv2 [24], Residual Net [9]for YOLOv3 [25]) and optimize the implementation for bestpractice. Currently, YOLOv5 [7] holds the best trade-offperformance with AP on COCO at , over the past two years, the major ad-vances in object detection academia have focused onanchor-free detectors [29, 40, 14], advanced label assign-ment strategies [37, 36, 12, 41, 22, 4], and end-to-end(NMS-free) detectors [2, 32, 39].
3 These have not been inte-grated into YOLO families yet, as YOLOv4 and YOLOv51we choose the YOLOv5-L model at640 640resolution and test themodel with FP16-precision and batch=1 on a V100 to align the settings ofYOLOv4 [1] and YOLOv4-CSP [30] for a fair comparison1 [ ] 6 Aug 2021are still anchor-based detectors with hand-crafted assigningrules for s what brings us here, delivering those recent ad-vancements to YOLO series with experienced optimiza-tion. Considering YOLOv4 and YOLOv5 may be a littleover-optimized for the anchor-based pipeline, we chooseYOLOv3 [25] as our start point (we set YOLOv3-SPP asthe default YOLOv3). Indeed, YOLOv3 is still one of themost widely used detectors in the industry due to the limitedcomputation resources and the insufficient software supportin various practical shown in Fig. 1, with the experienced updates ofthe above techniques, we boost the YOLOv3 to (YOLOX-DarkNet53) on COCO with640 640res-olution, surpassing the current best practice of YOLOv3( AP, ultralytics version2) by a large margin.
4 More-over, when switching to the advanced YOLOv5 architec-ture that adopts an advanced CSPNet [31] backbone and anadditional PAN [19] head, YOLOX-L achieves APon COCO with640 640resolution, outperforming thecounterpart YOLOv5-L by AP. We also test our de-sign strategies on models of small size. YOLOX-Tiny andYOLOX-Nano (only parameters and FLOPs)outperform the corresponding counterparts YOLOv4-Tinyand NanoDet3by 10% AP and AP, have released our code , with ONNX,TensorRT, NCNN and Openvino supported. One more thingworth mentioning, we won the 1st Place on Streaming Per-ception Challenge (Workshop on Autonomous Driving atCVPR 2021) using a single YOLOX-L YOLOX-DarkNet53We choose YOLOv3 [25] with Darknet53 as our base-line. In the following part, we will walk through the wholesystem designs in YOLOX step by detailsOur training settings are mostlyconsistent from the baseline to our final model.
5 We trainthe models for a total of 300 epochs with 5 epochs warm-up on COCO train2017[17]. We use stochastic gradi-ent descent (SGD) for training. We use a learning rate oflr BatchSize/64 (linear scaling [8]), with a initiallr= and the cosine lr schedule. The weight decay is the SGD momentum is The batch size is 128 bydefault to typical 8-GPU devices. Other batch sizes in-clude single GPU training also work well. The input sizeis evenly drawn from 448 to 832 with 32 strides. FPS and2 HeadDecoupled HeadVanilla ( ) ( )Table 1: The effect of decoupled head for end-to-end YOLOin terms of AP (%) on in this report are all measured with FP16-precisionand batch=1 on a single Tesla baselineOur baseline adopts the architec-ture of DarkNet53 backbone and an SPP layer, referredto YOLOv3-SPP in some papers [1, 7].
6 We slightlychange some training strategies compared to the orig-inal implementation [25], adding EMA weights updat-ing, cosine lr schedule, IoU loss and IoU-aware use BCE Loss for trainingclsandobjbranch,and IoU Loss for gen-eral training tricks are orthogonal to the key improve-ment of YOLOX, we thus put them on the , we only conductRandomHorizontalFlip,ColorJittera nd multi-scale for data augmentation anddiscard theRandomResizedCropstrategy, because wefound theRandomResizedCropis kind of overlappedwith the planned mosaic augmentation. With those en-hancements, our baseline achieves AP on COCOval,as shown in Tab. headIn object detection, the conflict betweenclassification and regression tasks is a well-known prob-lem [27, 34]. Thus the decoupled head for classificationand localization is widely used in the most of one-stage andtwo-stage detectors [16, 29, 35, 34].
7 However, as YOLO series backbones and feature pyramids ( , FPN [13],PAN [20].) continuously evolving, their detection heads re-main coupled as shown in Fig. two analytical experiments indicate that the coupleddetection head may harm the performance. 1). ReplacingYOLO s head with a decoupled one greatly improves theconverging speed as shown in Fig. 3. 2). The decoupledhead is essential to the end-to-end version of YOLO (willbe described next). One can tell from Tab. 1, the end-to-end property decreases by AP with the coupled head,while the decreasing reduces to AP for a decoupledhead. We thus replace the YOLO detect head with a lite de-coupled head as in Fig. 2. Concretely, it contains a1 1conv layer to reduce the channel dimension, followed bytwo parallel branches with two3 3conv layers respec-tively. We report the inference time with batch=1 on V100in Tab.
8 2 and the lite decoupled head brings additional ( ms).2! # 1024512256 FPNfeature!5!4!3! # #&'( *+ -+#&'( *+ 4+#&'( *+ ! # 256 2! # 256 2 Cls.! # C! # 4! # ~v5 CoupledHeadYOLOXD ecoupledHeadFeature1 1conv3 3conv! # 256 Figure 2: Illustration of the difference between YOLOv3 head and the proposed decoupled head. For each level of FPNfeature, we first adopt a1 1conv layer to reduce the feature channel to 256 and then add two parallel branches with two3 3conv layers each for classification and regression tasks respectively. IoU branch is added on the regression AP (%)EpochsDecoupled headYOLO headFigure 3: Training curves for detectors with YOLOv3 heador decoupled head. We evaluate the AP on COCO valevery10 epochs. It is obvious that the decoupled head convergesmuch faster than the YOLOv3 head and achieves better re-sult data augmentationWe add Mosaic and MixUpinto our augmentation strategies to boost YOLOX s per-formance.)))
9 Mosaic is an efficient augmentation strategyproposed by ultralytics-YOLOv32. It is then widely usedin YOLOv4 [1], YOLOv5 [7] and other detectors [3].MixUp [10] is originally designed for image classificationtask but then modified in BoF [38] for object detection train-ing. We adopt the MixUp and Mosaic implementation inour model and close it for the last 15 epochs, AP in Tab. 2. After using strong data augmentation,we found ImageNet pre-training is no more beneficial,wethus train all the following models from YOLOv4 [1] and YOLOv5 [7] fol-low the original anchor-based pipeline of YOLOv3 [25].However, the anchor mechanism has many known prob-lems. First, to achieve optimal detection performance, oneneeds to conduct clustering analysis to determine a set ofoptimal anchors before training. Those clustered anchorsare domain-specific and less generalized.
10 Second, anchormechanism increases the complexity of detection heads, aswell as the Number of predictions for each image. On someedge AI systems, moving such large amount of predictionsbetween devices ( , from NPU to CPU) may become apotential bottleneck in terms of the overall detectors [29, 40, 14] have developedrapidly in the past two year. These works have shownthat the performance of anchor-free detectors can be on parwith anchor-based detectors. Anchor-free mechanism sig-nificantly reduces the Number of design parameters whichneed heuristic tuning and many tricks involved ( , An-chor Clustering [24], Grid Sensitive [11].) for good per-formance, making the detector, especially its training anddecoding phase,considerablysimpler [29].Switching YOLO to an anchor-free manner is quite sim-ple. We reduce the predictions for each location from 3 to 1and make them directly predict four values, , two offsetsin terms of the left-top corner of the grid, and the heightand width of the predicted box.
![arXiv:0706.3639v1 [cs.AI] 25 Jun 2007](/cache/preview/4/1/3/9/3/1/4/b/thumb-4139314b93ef86b7b4c2d05ebcc88e46.jpg)

![arXiv:1301.3781v3 [cs.CL] 7 Sep 2013](/cache/preview/4/d/5/0/4/3/4/0/thumb-4d504340120163c0bdf3f4678d8d217f.jpg)
![@google.com arXiv:1609.03499v2 [cs.SD] 19 Sep 2016](/cache/preview/c/3/4/9/4/6/9/b/thumb-c349469b499107d21e221f2ac908f8b2.jpg)